Spring batch sql
프로젝트에서 지도와 관련된 부스 정보를 저장할 때, 각 부스가 운영되는 일차에 해당하는 날짜 정보를 별도의 매핑 테이블에 저장할 필요가 있었습니다. 기존 구현 방식의 SQL문을 살펴보니, 하나의 부스를 저장할 때 운영 날짜가 N개 있다면, 부스 정보를 저장하는 1개의 Insert SQL 이외에도 운영 날짜와 부스를 연결하는 매핑 데이터를 저장하는 Insert SQL이 N개 발생하는 문제를 발견했습니다. 이 글에서는 이런 N개의 Insert 문을 해결한 과정을 작성해보려고합니다.
1. 부스 정보를 저장하는 통합 테스트 코드 작성하기
가장 먼저 테스트 코드를 작성하여 로깅과 디버깅 작업을 용이하게 만들었습니다. @SpringBootTest환경에서 수행했으며 Test용 applicaation.yml파일을 만들어 mysql 환경에서 테스트하였습니다. 대략적인 테스트 코드는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Test
void 지도정보생성시_N개의_DurationMap_생성_테스트() {
MapCreateDto mapCreateDto = MapCreateDto.builder()
.buttonInfo(new ButtonInfoDto())
.operationInfo(new OperationInfoDto())
.locationInfo(new LocationInfoDto())
.addDurationIds(durationIds)
.build();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
mapService.create(mapCreateDto, mapCategory.getId());
stopWatch.stop();
System.out.println("수행시간(ms): " + stopWatch.getTotalTimeMillis());
}
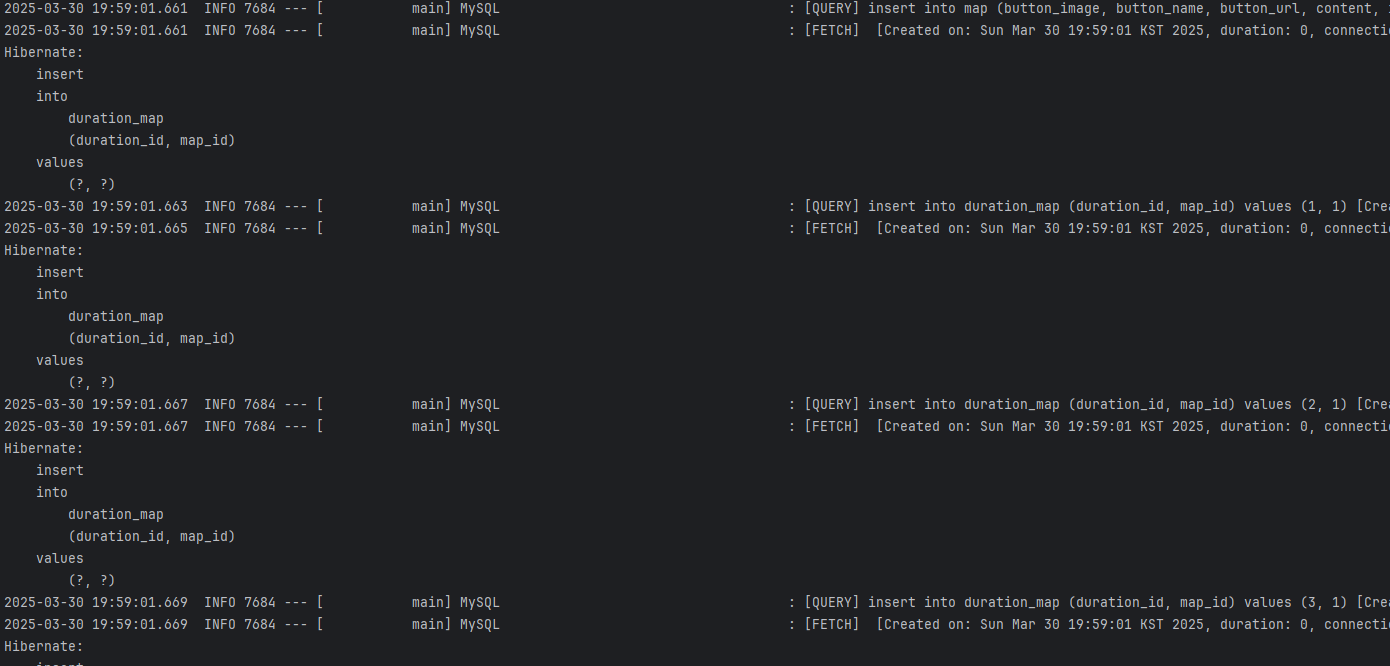
테스트 대상은 mapService.create() 메서드이며, 이 메서드 내에서 발생하는 insert 문들의 개수에 따라 수행 시간이 달라지는 것을 확인하기 위해 StopWatch를 활용했습니다. 5개의 DurationMap을 저장하는 테스트에서는 아래 사진과 같이 SQL이 발생하였습니다.
2. jdbc.batch_size: 옵션으로 시도하기
처음에는 application.yml 파일에 다음 설정을 추가하여 Hibernate 배치 기능을 활성화하려고 시도했습니다.
1
2
3
4
5
6
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 100
하지만 이 설정을 적용한 후 로그를 확인해보니, 기대했던 배치 처리가 일어나지 않고 기존과 동일하게 개별 Insert SQL이 실행되고 있었습니다.
원인을 분석해본 결과, JPA에서 @GeneratedValue(strategy = GenerationType.IDENTITY) 전략을 사용하고 있었던 것이 문제였습니다. 이 전략은 MySQL 기준으로 AUTO_INCREMENT를 활용하여 DB에서 기본 키를 자동 생성하게 되는데, 이 방식은 Hibernate에서 배치 Insert를 사용할 수 없도록 만듭니다. 엔티티의 PK 값은 실제로 데이터베이스에 레코드를 INSERT한 후에만 알 수 있어 행이 실제로 데이터베이스에 삽입되기 전까지는 식별자 값이 존재하지 않았습니다. 따라서, 엔티티의 PK를 모른 채로 영속성 컨텍스트에 계속 놔둘 수 없으므로, 보통 insert를 딜레이(batch로 묶어서 한꺼번에)를 하지 못하고, 엔티티마다 즉시 insert를 실행해 버리는 것이 문제였습니다.
실제로 Hibernate 공식 문서를 참고해보면, IDENTITY 전략을 사용하는 경우 Hibernate는 해당 엔티티에 대한 Insert 구문을 배치 처리할 수 없다는 점이 명시되어 있었습니다. 따라서 배치를 적용하기 위해서는 ID 전략을 변경하거나, 매핑 대상 엔티티에만 별도의 저장 로직을 구성할 필요가 있었습니다.
3. PK 전략 변경 vs jdbcTemplate batchUpdate
다음으로 고려했던 방법 중 하나는 PK 생성 전략을 변경하는 것이었습니다.
IDENTITY 전략을 TABLE 방식으로 변경하면 DB에 독립적이며 모든 DB에서 사용할 수 있다는 장점이 있습니다. 하지만, 별도의 키 저장 테이블을 조회하고 업데이트하는 작업이 필요하고, 멀티 스레드 환경에서는 동시 접근으로 인해 락이 걸려 병목이 발생할 수 있다는 단점이 존재합니다.
또 다른 방법으로는, PK를 AUTO_INCREMENT가 아닌 ULID나 순차성을 가진 UUID로 생성하는 방식도 고려해 보았습니다. 이 방식은 민감한 정보를 다룰 때에는 유용하지만, 지금처럼 누구나 접근할 수 있는 부스 정보에서는 오히려 PK 크기 증가에 따른 부담이 있었습니다. 특히 MySQL의 클러스터링 인덱스 구조에서는 PK가 커질수록 세컨더리 인덱스도 함께 커지기 때문에 성능 측면에서 불리할 수 있다고 생각하였습니다.
결국 최종적으로 선택한 방법은 JdbcTemplate.batchUpdate()를 활용하는 것이었습니다. 이 방식은 기존 JPA 구조를 크게 변경하지 않아도 적용이 가능하며, 설정과 사용 방식도 비교적 단순해서 도입 난이도가 낮았습니다.
4. jdbcTemplate batchUpdate 코드 작성 및 시간 측정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
@Repository
@RequiredArgsConstructor
public class DurationMapJdbcRepository {
private final JdbcTemplate jdbcTemplate;
public void batchInsertMapDurations(Long mapId, List<Duration> durations) {
if (durations == null || durations.isEmpty()) {
return;
}
final String sql = "INSERT INTO duration_map (map_id, duration_id) VALUES (?, ?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setLong(1, mapId);
ps.setLong(2, durations.get(i).getId());
}
@Override
public int getBatchSize() {
return durations.size();
}
});
}
}
JdbcTemplate.batchUpdate() 메서드를 활용하여 ID를 제외한 필요한 필드만으로 SQL을 구성하였고, 기존에 JPA의 쓰기 지연에 의존하던 방식 대신 이 메서드를 통해 직접 Insert를 수행하도록 변경했습니다.
변경된 mapService.create() 메서드는 해당 Repository의 배치 Insert 메서드를 호출하도록 수정하였고, 앞서 작성한 테스트 코드를 통해 실제 SQL 실행 로그를 확인해보았습니다. 아래는 로그 예시입니다:
1
2
3
4
5
INSERT INTO duration_map (map_id, duration_id)
VALUES (1, 1),(1, 2),(1, 3),(1, 4),(1, 5)
[Created on: Sun Mar 30 21:07:16 KST 2025, duration: 1, connection-id: 88, statement-id: 0, resultset-id: 0,com.zaxxer.hikari.pool.ProxyStatement.executeBatch
(ProxyStatement.java:127)]
이러한 로그를 출력하기 위해 테스트 전용 application.yml에서 JDBC URL에 아래와 같은 옵션을 추가했습니다:
1
2
jdbc:mysql://localhost:3306/eventerdb?characterEncoding=UTF-8&rewriteBatchedStatements=true&profileSQL=true
&logger=Slf4JLogger&maxQuerySizeToLog=2000
테스트 결과, 100개의 데이터를 기준으로 수행 시간을 측정했을 때 기존 205ms에서 약 90ms까지 줄어들며 약 55% 이상의 성능 개선을 확인할 수 있었습니다.
5. 마무리하며
실제 프로젝트에서 부스 정보 추가는 하나의 축제 사이트를 제작할 때마다 반복적으로 발생하는 주요 기능 중 하나였습니다. 특히 축제의 기간이 길어질수록, 하나의 부스를 등록할 때 함께 저장해야 하는 날짜 매핑 데이터의 양도 많아져, 단일 Insert 방식으로는 성능 저하가 발생할 수밖에 없었습니다.
이번 작업을 통해 JdbcTemplate.batchUpdate()를 활용하여 이러한 문제를 효과적으로 해결할 수 있었고, 실제로 수행 시간도 약 205ms에서 90ms로 크게 단축되는 결과를 얻었습니다. 쿼리 묶음 처리로 인해 DB에 전달되는 쿼리 수 자체가 줄어든 것이 주요 포인트라고 생각하고 실제 운영환경에서는 네트워크 시간까지 고려한다면 수행시간이 크게 단축되었을 것이라고 판단했습니다.
향후에는 이와 유사하게 반복적으로 다량의 데이터를 저장하는 기능들에 대해서도 batch insert를 적용하여 전반적인 성능을 개선할 계획입니다.
이번 작업을 계기로 @GeneratedValue(strategy = GenerationType.IDENTITY) 방식이 배치 처리에 미치는 영향, 그리고 JPA의 영속성 컨텍스트가 flush 타이밍에 미치는 영향을 깊이 이해할 수 있었습니다. 단순히 기능 구현을 넘어서 JPA와 JDBC 내부 동작 원리를 탐구할 수 있는 좋은 기회였다고 생각합니다.